CrateDB: Use Docker Compose for CrateDB

"CrateDB is a distributed SQL database management system that integrates a fully searchable document-oriented data store."
To see if CrateDB fulfills your needs, the easiest way is to use create a Docker container using Docker Compose. Here's how I do that:
services:
db:
image: crate
hostname: cratedb
command: ["crate",
"-Cnode.name=cratedb01",
"-Cauth.host_based.enabled=true",
"-Cauth.host_based.config.0.method=trust",
"-Cauth.host_based.config.0.address=_local_",
"-Cauth.host_based.config.0.user=crate",
"-Cauth.host_based.config.99.method=password"
]
deploy:
replicas: 1
restart_policy:
condition: on-failure
environment:
- CRATE_HEAP_SIZE=2g
restart: always
ports:
- 5432:5432
- 4200:4200Let's pull the image:
# docker compose pull[+] Pulling 10/10
✔ db Pulled 6.5s
✔ 05b4d6cb1ce9 Pull complete 3.0s
✔ 431bb707880e Pull complete 3.4s
✔ 462386bbd109 Pull complete 4.6s
✔ 40dfb4e6e9d4 Pull complete 4.6s
✔ c3a0577704a3 Pull complete 4.7s
✔ 4f4fb700ef54 Pull complete 4.8s
✔ 9a3c98bdf27f Pull complete 4.8s
✔ a33845a0ade8 Pull complete 4.8s
✔ 559b3b1a4775 Pull complete 4.9sNow, we start it and look at the log files:
# docker compose up -d
# docker compose logs -f[+] Running 1/1
✔ Container cratedb-db-1 Started 9.6s
db-1 | WARNING: Using incubator modules: jdk.incubator.vector
db-1 | Jul 10, 2025 8:30:15 AM org.apache.lucene.store.MemorySegmentIndexInputProvider <init>
db-1 | INFO: Using MemorySegmentIndexInput and native madvise support with Java 21 or later; to disable start with -Dorg.apache.lucene.store.MMapDirectory.enableMemorySegments=false
db-1 | [2025-07-10T08:30:15,711][INFO ][o.e.e.NodeEnvironment ] [cratedb01] using [1] data paths, mounts [[/data (/dev/sda1)]], net usable_space [28.1gb], net total_space [96.7gb], types [ext4]
db-1 | [2025-07-10T08:30:15,714][INFO ][o.e.e.NodeEnvironment ] [cratedb01] heap size [2gb], compressed ordinary object pointers [true]
db-1 | [2025-07-10T08:30:15,738][INFO ][o.e.n.Node ] [cratedb01] node name [cratedb01], node ID [neGYaUZhQQWGgh5QllKpWw], cluster name [crate]
db-1 | [2025-07-10T08:30:15,740][INFO ][o.e.n.Node ] [cratedb01] version[5.10.10], pid[1], build[5fef4e0/NA], OS[Linux/6.14.0-1005-oracle/aarch64], JVM[Eclipse Adoptium/OpenJDK 64-Bit Server VM/23.0.2+7]
db-1 | Jul 10, 2025 8:30:16 AM org.apache.lucene.internal.vectorization.PanamaVectorizationProvider <init>
db-1 | INFO: Java vector incubator API enabled; uses preferredBitSize=128; FMA enabled
db-1 | [2025-07-10T08:30:16,996][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [cr8-copy-s3]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [crate-copy-azure]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [crate-functions]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [crate-jmx-monitoring]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [crate-lang-js]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [es-analysis-common]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [es-analysis-phonetic]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [es-repository-azure]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [io.crate.plugin.SrvPlugin]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [io.crate.udc.plugin.UDCPlugin]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [org.elasticsearch.discovery.ec2.Ec2DiscoveryPlugin]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [org.elasticsearch.plugin.repository.url.URLRepositoryPlugin]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [org.elasticsearch.repositories.s3.S3RepositoryPlugin]
db-1 | [2025-07-10T08:30:16,997][INFO ][o.e.p.PluginsService ] [cratedb01] loaded plugin [repository-gcs]
db-1 | SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
db-1 | SLF4J: Defaulting to no-operation (NOP) logger implementation
db-1 | SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
db-1 | [2025-07-10T08:30:18,581][INFO ][o.e.d.DiscoveryModule ] [cratedb01] using discovery type [zen] and seed hosts providers [settings]
db-1 | [2025-07-10T08:30:19,436][INFO ][psql ] [cratedb01] PSQL SSL support is disabled.
db-1 | [2025-07-10T08:30:19,752][WARN ][o.e.g.DanglingIndicesState] [cratedb01] gateway.auto_import_dangling_indices is disabled, dangling indices will not be detected or imported
db-1 | [2025-07-10T08:30:19,832][INFO ][o.e.n.Node ] [cratedb01] initialized
db-1 | [2025-07-10T08:30:19,833][INFO ][o.e.n.Node ] [cratedb01] starting ...
db-1 | [2025-07-10T08:30:19,926][INFO ][psql ] [cratedb01] publish_address {172.18.0.13:5432}, bound_addresses {[::1]:5432}, {127.0.0.1:5432}, {172.18.0.13:5432}
db-1 | [2025-07-10T08:30:19,937][INFO ][o.e.h.n.Netty4HttpServerTransport] [cratedb01] publish_address {172.18.0.13:4200}, bound_addresses {[::1]:4200}, {127.0.0.1:4200}, {172.18.0.13:4200}
db-1 | [2025-07-10T08:30:19,949][INFO ][o.e.t.TransportService ] [cratedb01] publish_address {172.18.0.13:4300}, bound_addresses {[::1]:4300}, {127.0.0.1:4300}, {172.18.0.13:4300}
db-1 | [2025-07-10T08:30:20,161][INFO ][o.e.b.BootstrapChecks ] [cratedb01] bound or publishing to a non-loopback address, enforcing bootstrap checks
db-1 | [2025-07-10T08:30:20,173][INFO ][o.e.c.c.ClusterBootstrapService] [cratedb01] no discovery configuration found, will perform best-effort cluster bootstrapping after [3s] unless existing master is discovered
db-1 | [2025-07-10T08:30:23,178][INFO ][o.e.c.c.Coordinator ] [cratedb01] setting initial configuration to VotingConfiguration{neGYaUZhQQWGgh5QllKpWw}
db-1 | [2025-07-10T08:30:23,338][INFO ][o.e.c.s.MasterService ] [cratedb01] elected-as-master ([1] nodes joined)[{cratedb01}{neGYaUZhQQWGgh5QllKpWw}{UExscns_QHmF25Mru-bKNQ}{172.18.0.13}{172.18.0.13:4300}{dm}{http_address=172.18.0.13:4200} elect leader, _BECOME_MASTER_TASK_, _FINISH_ELECTION_], term: 1, version: 1, reason: master node changed {previous [], current [{cratedb01}{neGYaUZhQQWGgh5QllKpWw}{UExscns_QHmF25Mru-bKNQ}{172.18.0.13}{172.18.0.13:4300}{dm}{http_address=172.18.0.13:4200}]}
db-1 | [2025-07-10T08:30:23,383][INFO ][o.e.c.c.CoordinationState] [cratedb01] cluster UUID set to [Bp8qbiJaQ9SWxqa2rWQkpw]
db-1 | [2025-07-10T08:30:23,414][INFO ][o.e.c.s.ClusterApplierService] [cratedb01] master node changed {previous [], current [{cratedb01}{neGYaUZhQQWGgh5QllKpWw}{UExscns_QHmF25Mru-bKNQ}{172.18.0.13}{172.18.0.13:4300}{dm}{http_address=172.18.0.13:4200}]}, term: 1, version: 1, reason: Publication{term=1, version=1}
db-1 | [2025-07-10T08:30:23,428][INFO ][o.e.n.Node ] [cratedb01] started
db-1 | [2025-07-10T08:30:23,455][INFO ][o.e.g.GatewayService ] [cratedb01] recovered [0] indices into cluster_stateWe can now start the CrateDB client crash from within the container:
# docker exec -u crate -ti cratedb-db-1 crash
CONNECT OK
cr>We can see that the information schema exists like in PostgreSQL:
cr> select * from information_schema.tables;
+------------+--------+--------------+---------------+--------------------+------------------+----------------+----------------------+-----------------------+------------------------------+----------+---------------+-------------------------+--------------------+------------+---------+
| blobs_path | closed | clustered_by | column_policy | number_of_replicas | number_of_shards | partitioned_by | reference_generation | routing_hash_function | self_referencing_column_name | settings | table_catalog | table_name | table_schema | table_type | version |
+------------+--------+--------------+---------------+--------------------+------------------+----------------+----------------------+-----------------------+------------------------------+----------+---------------+-------------------------+--------------------+------------+---------+
| NULL | NULL | NULL | strict | NULL | NULL | NULL | SYSTEM GENERATED | NULL | NULL | NULL | crate | character_sets | information_schema | BASE TABLE | NULL |
| NULL | NULL | NULL | strict | NULL | NULL | NULL | SYSTEM GENERATED | NULL | NULL | NULL | crate | columns | information_schema | BASE TABLE | NULL |Let's create a user:
cr> CREATE USER martin WITH (password = 'XxXxXxXx');
CREATE OK, 1 row affected (0.222 sec)
cr> GRANT ALL PRIVILEGES TO martin;
GRANT OK, 4 rows affected (0.073 sec)Now, we can also use the PostgreSQL client psql to connect to the database:
psql -p 5432 -h <hostname> -U martinPassword for user martin:
psql (17.5 (Ubuntu 17.5-1.pgdg24.04+1), server 14.0)
Type "help" for help.
martin=>Basic functions like in PostgreSQL work
cr> show tables;
+------------+
| table_name |
+------------+
+------------+
SHOW 0 rows in set (0.023 sec)but commands like
\dt+\l
do not:
martin=> \l
ERROR: Unknown function: pg_catalog.array_length(d.datacl, 1)
CONTEXT: io.crate.metadata.Functions.raiseUnknownFunction(Functions.java:370)Let's create a simple table like this:
cr> create table table_one(id int,value char);
CREATE OK, 1 row affected (1.037 sec)Now, one table exists:
cr> show tables;
+------------+
| table_name |
+------------+
| table_one |
+------------+
SHOW 1 row in set (0.004 sec)No matter if we have many or only one node, we can see that CrateDB automatically created shards:
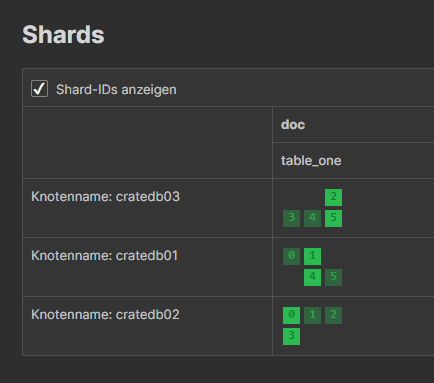
If you want to know more, have a look at the CrateDB commands documentation.
As the port 4200 is exposed, we can also connect to the web console using http://<servername>:4200:
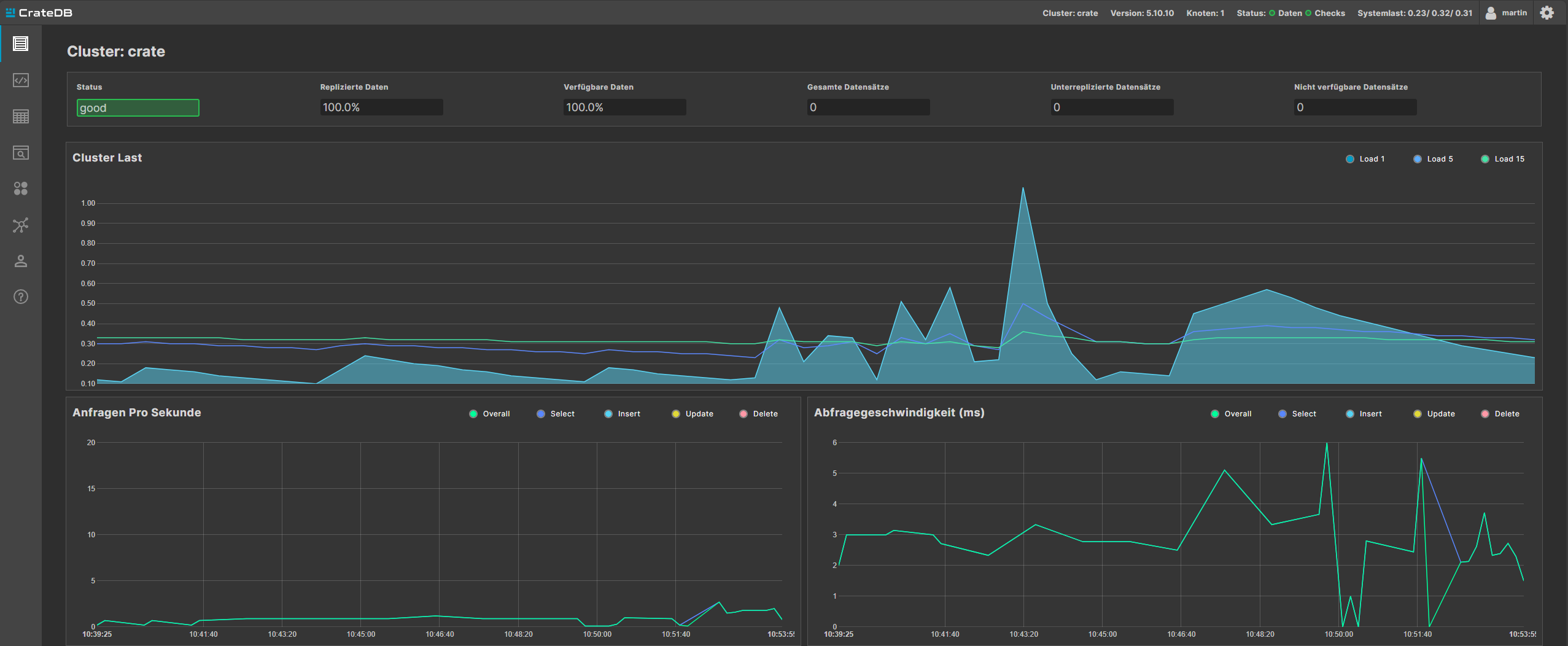
This is just a single node, but you can also follow the CrateDB documentation to create a cluster with more nodes. Then, your web console will like this:
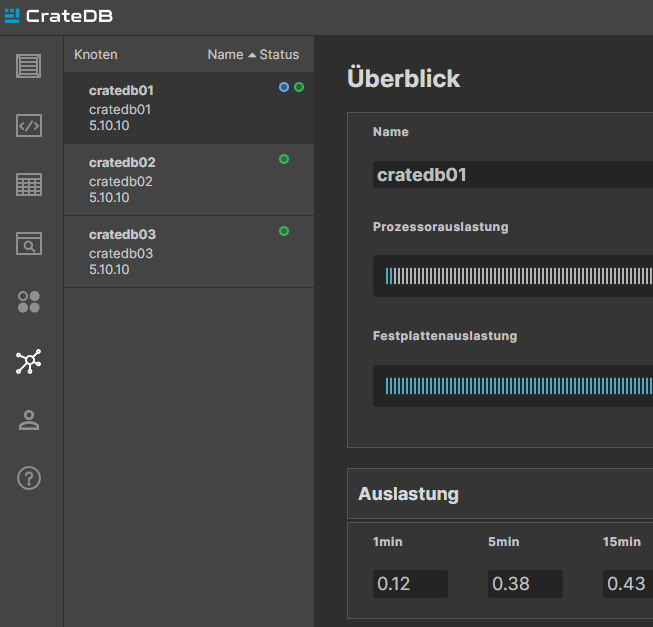
The blue circle indicates which one the primary node is.
Being an Oracle DBA, I'm quite impressed how easy it is to create a cluster with nodes. Additionally, there's no need to configure sharding - it just runs out of the box...
But wait - what about High Availability? In this case, each CrateDB node holds a part of the data. What if one fails? Data would be lost...
In my docker-compose.yml, the value for replicas is set to 1. That means, that every shard has a primary data shard (displayed in light green), and a replica data shard (displayed in dark green). Setting it to a higher number would mean that there are created more replica shards for every primary shard. This increses the fault tolerance, but needs more space. Setting it to 0 does not work from within Docker. But if you want to specify the amount of shards, or the key by which you want to shard, you can do that as a parameter in the create table statement:
cr> create table table_two(id int, value char) clustered by (id) into 2 shards;
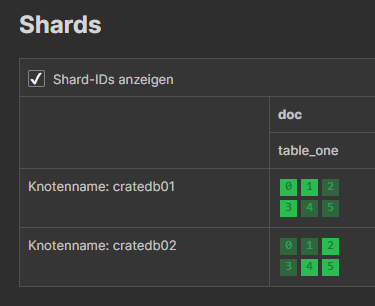
CREATE OK, 1 row affected (0.441 sec)The data is now distributed to 2 shards, not to 3. And also replica shards are create only on 2 nodes:

And we can also create a table with only one shard:
cr> create table table_three(id int, value char) clustered by (id) into 1 shards;It's primary data is on one node, the replica data on another:

But what if one node fails? Then we get an information about that (I stopped node 3):
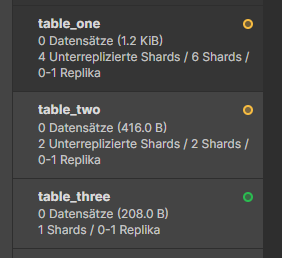
The creen circle shows that the full data as well as the replica is available. The yellow circle shows that data is available, but not enough replicas to be fully fault tolerant.
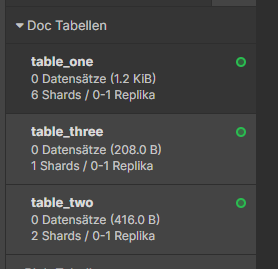
But after a few moments, data is replicated across the existing nodes, so that data is fully available, and fault tolerance is ensured:
After node 3 is started, data is again automatically replicated between the nodes:
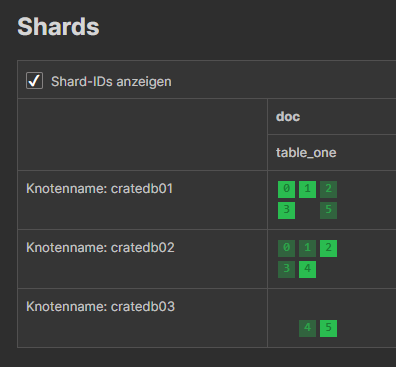
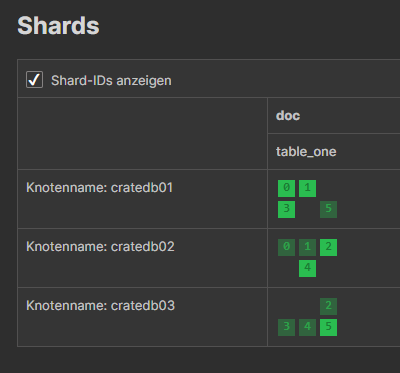
So stopping nodes, i. e. for maintenance, is not a big problem - as long as there are enough nodes left to fullfil the requirements: at least 2 nodes are needed if replicas is set to 1 (one for primary data, one for replica data). If replicas is set to 2, at least 3 nodes would be needed.
But changing shards can also be done with existing tables. For example, if you want to increase the number of replicas, you can do it like this:
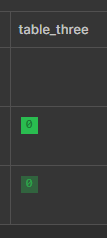
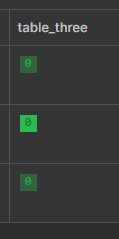
Now increase the replicas:
cr> alter table table_three SET (number_of_replicas = 2);
ALTER OK, -1 rows affected (0.240 sec)Now, the table has one primary and two replica data shards:
Conclusion
CrateDB is a great solution for a cluster with horizontal data distribution. It supports many functionalities provided by PostgreSQL. In contrast to Patroni cluster, many nodes can support read/write operations - Patroni only allows one node for read/write operations, all other nodes can be used for read-only operations.